ใช้ GPU อย่างมือโปร: เทคนิคจัดสรรทรัพยากรผ่าน Docker สู่ธุรกิจยุคใหม่

TL;DR
ในบทความ "AI ช่วยเขียนโค้ดแบบที่ไม่ง้อ Copilot" เราได้พูดถึงการใช้ Local LLM เพื่อเพิ่มประสิทธิภาพในการเขียนโค้ด ซึ่งสามารถอ่านเพิ่มเติมได้ที่ (AI ช่วยเขียนโค้ดแบบที่ไม่ง้อ Copilot) ครั้งนี้ เราจะขยายความต่อด้วยการจัดสรรทรัพยากร GPUs ผ่าน Docker เพื่อรัน Local LLM ให้เหมาะกับการประมวลผลข้อมูลขนาดใหญ่ การฝึกสอน Deep Learning และการเรนเดอร์กราฟิกขั้นสูง พร้อมตัวอย่าง config สำหรับการใช้ multiple GPUs กับ Ollama container รวมถึงเหตุผลที่ธุรกิจควรให้ความสำคัญกับเรื่องนี้
Ollama เป็นแพลตฟอร์มที่ช่วยให้การรันและจัดการ LLMs บนเครื่อง โลคอล เป็นเรื่องง่าย รองรับ GPU acceleration และสามารถปรับแต่งให้เหมาะกับงานเฉพาะทางได้
ทำไมต้องจัดสรร GPUs ใน Docker?
การใช้งาน Docker ได้รับความนิยมอย่างแพร่หลายเนื่องจากความสะดวกในการจัดการ container ที่สามารถ deploy ได้อย่างรวดเร็วและสเกลได้ง่าย แต่เมื่อมีความต้องการด้านประสิทธิภาพการประมวลผลที่สูงขึ้น เช่น การประมวลผลข้อมูลเชิงลึก (deep learning) หรือการเรนเดอร์วิดีโอ คุณลักษณะของ GPUs จึงเข้ามามีบทบาทสำคัญ การจัดสรร GPUs ใน Docker ทำให้นักพัฒนาสามารถแบ่งปันและใช้ทรัพยากรที่มีอยู่ได้อย่างเต็มประสิทธิภาพโดยไม่ต้องเสียเวลาในการติดตั้งและกำหนดค่าเครื่องมือที่ซับซ้อน
การแยกและจัดสรร GPUs อย่างเหมาะสมมีข้อดีหลายประการ เช่น
- ประสิทธิภาพที่สูงขึ้น: การใช้งาน GPUs ในงานที่ต้องประมวลผลข้อมูลจำนวนมากสามารถเพิ่มความเร็วและลดเวลาในการประมวลผล
- การสเกลระบบ: เมื่อธุรกิจมีการเติบโตและต้องการประมวลผลข้อมูลที่เพิ่มขึ้น การจัดสรรทรัพยากรณ์ GPUs อย่างมีระบบจะช่วยให้สามารถเพิ่มจำนวน container ได้อย่างง่ายดาย
- การประหยัดต้นทุน: การใช้ container ที่มีการจัดสรรทรัพยากรณ์ GPUs อย่างเหมาะสมจะช่วยลดค่าใช้จ่ายในระยะยาว เพราะสามารถใช้ทรัพยากรณ์ที่มีอยู่ให้เกิดประโยชน์สูงสุด
ข้อดีสำหรับภาคธุรกิจ
- ความยืดหยุ่นและประสิทธิภาพในการประมวลผล ธุรกิจที่ต้องการประมวลผลข้อมูลขนาดใหญ่หรือใช้โมเดล AI ที่ซับซ้อนจะได้ประโยชน์จากการใช้ GPUs ใน Docker เนื่องจากสามารถเพิ่มประสิทธิภาพและลดเวลาที่ใช้ในการประมวลผล ซึ่งช่วยให้ธุรกิจสามารถแข่งขันในตลาดได้อย่างมีประสิทธิภาพ
- การจัดการทรัพยากรณ์ที่มีประสิทธิภาพ ด้วยการใช้ Docker ร่วมกับการจัดสรร GPUs ทำให้สามารถบริหารจัดการทรัพยากรณ์ที่มีอยู่ในระบบได้ดียิ่งขึ้น ไม่ว่าจะเป็นการแบ่งปัน GPUs ระหว่าง container หลาย ๆ ตัว หรือการเพิ่ม container ใหม่เมื่อมีความต้องการเพิ่มขึ้น ซึ่งเป็นการบริหารจัดการที่ช่วยลดต้นทุนและเพิ่มความสามารถในการสเกลระบบ
- ลดความซับซ้อนในการติดตั้งและกำหนดค่า การใช้ Docker ช่วยลดความยุ่งยากในการติดตั้งและกำหนดค่าเครื่องมือที่เกี่ยวข้องกับ GPU ซึ่งสำหรับธุรกิจที่มีการพัฒนาและ deploy ระบบอย่างรวดเร็วแล้วนั้น สิ่งนี้เป็นประโยชน์อย่างมาก โดยเฉพาะอย่างยิ่งในสภาพแวดล้อมที่ต้องการความยืดหยุ่นและรวดเร็วในการปรับตัว
- การรองรับเทคโนโลยีและนวัตกรรมใหม่ๆ การจัดสรร GPUs อย่างมีประสิทธิภาพช่วยให้ธุรกิจสามารถรองรับและนำเทคโนโลยีใหม่ ๆ เข้ามาใช้งานได้อย่างต่อเนื่อง ไม่ว่าจะเป็นการพัฒนาโมเดล AI ที่มีความซับซ้อนมากขึ้น หรือการประมวลผลข้อมูลที่มีปริมาณมากในเวลาที่จำกัด ซึ่งจะเป็นกุญแจสำคัญในการรักษาความได้เปรียบในการแข่งขัน
การใช้งาน Multiple GPUs สำหรับ Ollama Container
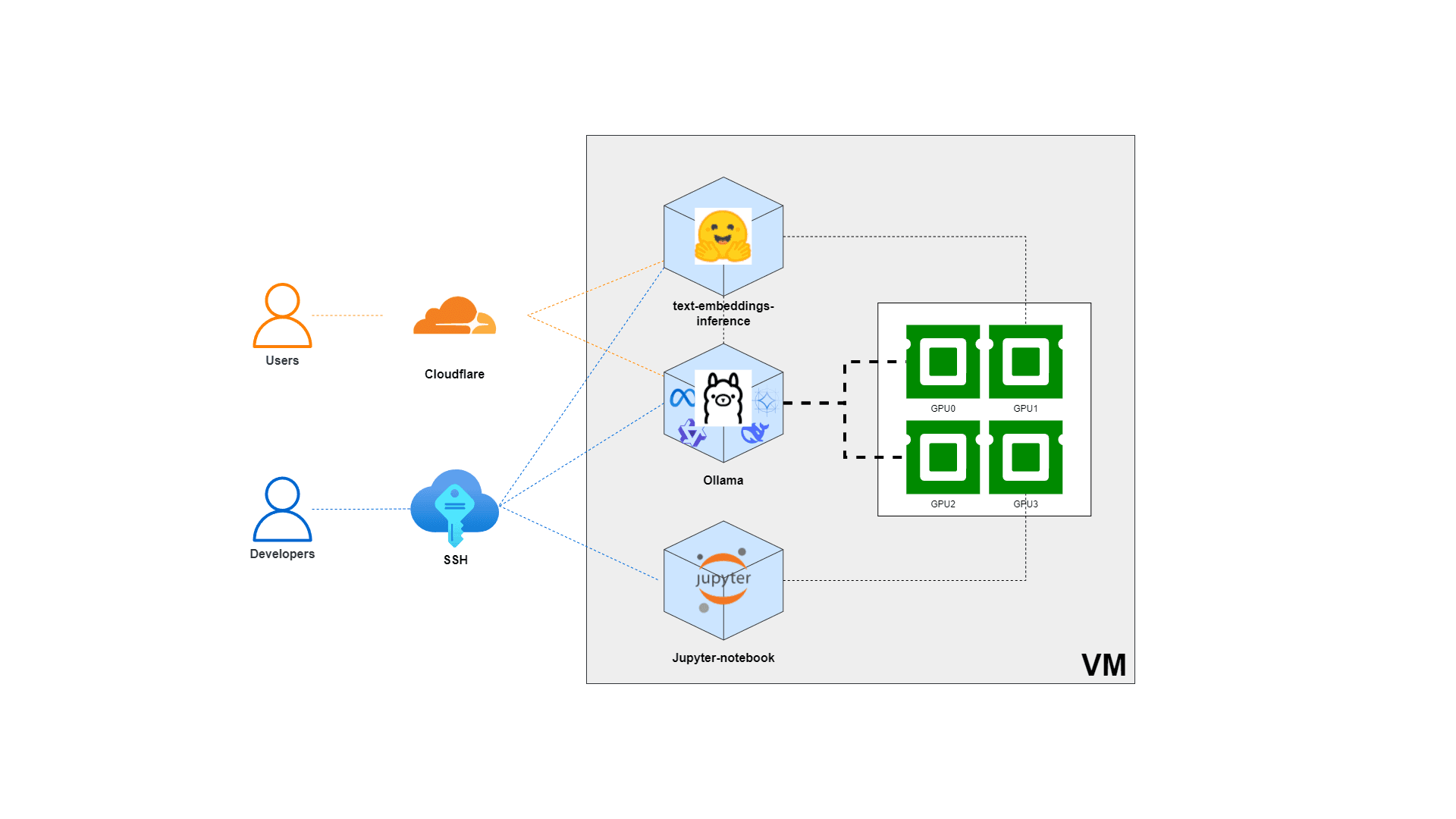
สมมติว่าเรามีเครื่องที่ติดตั้ง GPUs จำนวน 4 ตัว แต่ต้องการกำหนดให้ Ollama container ใช้งานเฉพาะ GPU 0 และ GPU 2 ซึ่ง GPUs ที่เหลือ (1, 3) ก็สามารถนำไปใช้งานได้กับ services อื่น ๆ ซึ่งในตัวอย่างนี้จะแสดงเฉพาะวิธีการ config สำหรับ Ollama container เราสามารถทำได้โดยการตั้งค่าผ่านไฟล์ docker-compose.yml ดังตัวอย่างต่อไปนี้:
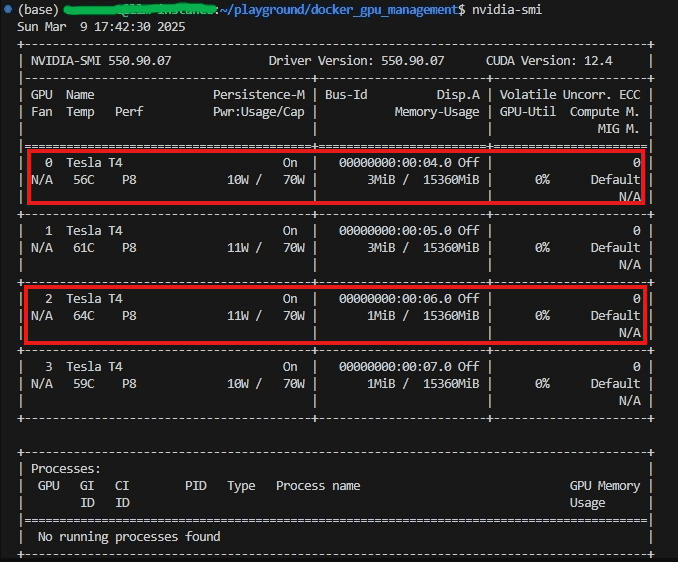
1. ทำการรันคำสั่ง nvidia-smi เพื่อเรียกดู GPUs ทั้งหมดที่มีอยู่ในเครื่อง
2. Config docker-compose สำหรับ Ollama container (โดยที่เราจะเลือกแค่ GPUs 0, 2 เพื่อมาใช้งานใน container)
version: '3.8'
services:
ollama:
container_name: ollama
image: ollama/ollama:latest # สามารถระบุเวอร์ชันเฉพาะได้ตามที่ต้องการ
ports:
- 11434:11434
volumes:
- ollama:/root/.ollama # สำหรับการเก็บข้อมูลและโมเดลที่ใช้งานแบบ persistent
restart: always
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0', '2']
capabilities: [gpu]
volumes:
ollama:3. รันคำสั่งเพื่อ start docker container (Ollama) และเข้าไปยังภายในของ container
docker compose up -d && \
docker exec -ti ollama bash4. ทำการโหลดโมเดลเพื่อมาทดลองรัน ในที่นี้เราเลือกเป็น deepseek-r1:32b
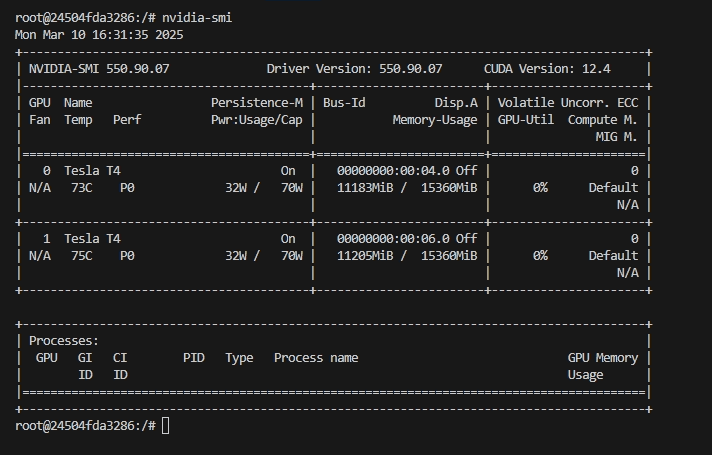
ollama run deepseek-r1:32b5. ทำการเรียกดู GPUs ภายใต้ Ollama container คำสั่ง nvidia-smi เราก็จะพบว่าภายในจะมี GPUs ที่เราจองไว้อยู่ 2 อัน และมี Memory-Usage ประมาณ 25 GB
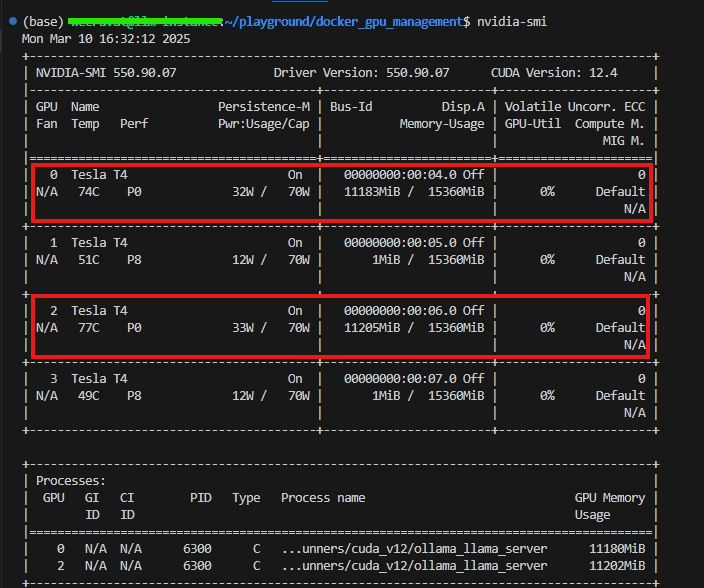
6. ออกจาก container และลองทำการรันคำสั่ง nvidia-smi เพื่อตรวจสอบว่าการจัดสรรทรัพยากรของเรานั้น config ได้ถูกต้องและมี Memory-Usage ประมาณ 25 GB เท่า ๆ กันกับภายใน container
ในตัวอย่างนี้ เราได้กำหนดค่า deploy.resources.reservations.devices ซึ่งช่วยให้ Docker สามารถจัดสรรทรัพยากรณ์ได้อย่างเหมาะสมตามที่ต้องการ
บทสรุป
การจัดสรรทรัพยากรณ์ GPUs สำหรับ Docker ไม่เพียงแต่เป็นวิธีที่ช่วยเพิ่มประสิทธิภาพในการประมวลผลข้อมูล แต่ยังเป็นเครื่องมือที่ช่วยลดต้นทุนและเพิ่มความยืดหยุ่นให้กับองค์กรอีกด้วย ด้วยการใช้ตัวอย่างการ config สำหรับ Ollama container ที่ใช้งาน GPU 0 และ GPU 2 เท่านั้น ธุรกิจสามารถปรับเปลี่ยนและขยายขีดความสามารถของระบบได้อย่างมีประสิทธิภาพในยุคที่การแข่งขันทางด้านเทคโนโลยีและนวัตกรรมเพิ่มขึ้นอย่างต่อเนื่อง
ธุรกิจที่มองหาแนวทางในการปรับปรุงการทำงานและลดต้นทุนจึงควรให้ความสำคัญกับการจัดสรรทรัพยากรณ์ GPUs เพราะจะช่วยให้การบริหารจัดการงานด้าน AI และการประมวลผลข้อมูลมีความคล่องตัวและตอบสนองต่อความต้องการของตลาดได้อย่างรวดเร็วและมีประสิทธิภาพ ด้วยเหตุนี้ การนำเทคโนโลยีการจัดสรรทรัพยากรณ์ GPUs ไปประยุกต์ใช้งานไม่เพียงแต่เป็นการลงทุนในเทคโนโลยีที่ทันสมัย แต่ยังเป็นการลงทุนในอนาคตที่เตรียมพร้อมรับมือกับการเปลี่ยนแปลงและความท้าทายใหม่ ๆ ในยุคดิจิทัลอย่างแท้จริง
---
AI DETA มีประสบการณ์และความเชี่ยวชาญในการออกแบบและพัฒนาระบบสารสนเทศ, การพัฒนาระบบ ERP และการปรับแต่ง Odoo ERP, การพัฒนาและจัดการ Cloud-Based Solution/Application, โซลูชันด้านข้อมูล การเรียนรู้ของเครื่องจักร และปัญญาประดิษฐ์ (Data/ML/AI Solution), รวมถึงการให้คำปรึกษา หรือ Outsource ให้แก่องค์กรต่าง ๆ และพวกเราพร้อมเป็นส่วนหนึ่งในการทำ Digital Transformation ให้กับองค์กรของคุณ
หากมีความสนใจให้พวกเราเป็นผู้พัฒนาระบบหรือให้คำปรึกษา หรือต้องการสอบถามอัตราค่าบริการต่าง ๆ สามารถติดต่อได้ทางอีเมล [email protected] หรือดูรายละเอียดได้ที่เว็บไซต์ https://aideta.com
---